Five Reasons To Consider The Server Side
22 June 2017
For the last decade web development has been moving away from the original server-side model to a client-side programming model, driven by the adoption of javascript and, in the last few years, the explosion of front-end SPA and component frameworks. Most new web projects starting today are going to at least entertain the idea of using client-side rendering coupled with some sort of JSON API.
In this article I’d like to give you a few reasons to consider sticking with a server-side architecture. As with all technical decisions there are a near infinite number of things to consider and each application is different, but I think that these areas in particular are worth considering, even if you decide not to go with a server side approach.
#1 - Simplicity
The first thing that can be said about the server-side approach is that it is simple: there are well known, tried and true approaches to most problems you face, and there weren’t a huge number of abstractions to deal with.
One of my favorite intercooler memes captures this:
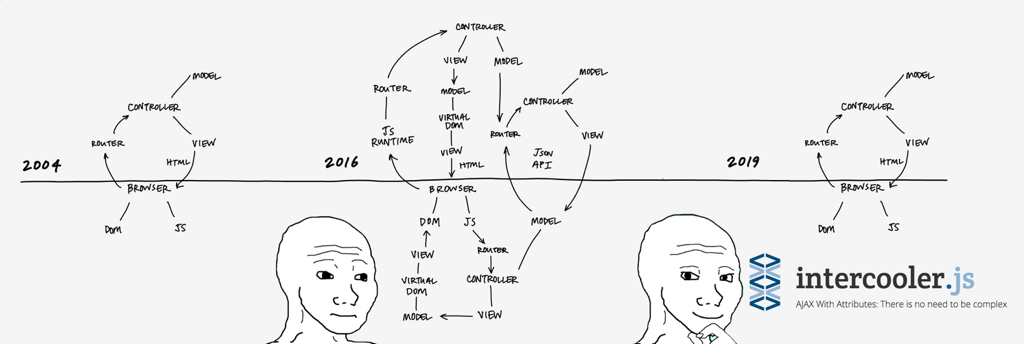
This exaggerates the situation for humorous effect, of course, but the point remains: the older server-side model was simpler to deal with. It fell down from a UX perspective, but luckily we have intercooler now to fix that.
As you try to preserve the complexity budget of your application, this is an often overlooked area to simplify. Intercooler, in particular, is designed to be incremental so you can apply as little as is necessary to achieve the UX you want, and only in the high value areas of your application.
#2 -Language Agnosticism
The browser is making progress towards multi-language support with things like WebAssembly, but the front end is Javascript-oriented and will be for the foreseeable future. I’m not going to argue over the merits or demerits of Javascript, but I will simply observe there are quite a few people who prefer other languages.
Fortunately, on the server side, you can use whatever language (and tool set) that you are most comfortable with. By using HTTP/HTML as your client/server communication medium, you are free to choose the best tool for your application domain, rather than being forced into either a multi-language project or a language that isn’t the best tool for your particular problem.
#3 -Security
This has been a tricky one for me to communicate well, but there are security considerations when you adopt a client-side programming model that many people seem to overlook. I will focus on two issues in particular:
You cannot trust any computations done on the client
The client side is an untrusted computing environment which is to say that you cannot trust any calculations that come from it. A hostile user can inspect your code and data structures and manipulate them in whatever manner they wish simply by firing up a console. This means that sensitive calculations done on the client side must be redone on the server side to verify the results. Data-level security constraints can help here to some extent, but complex calculations often do not lend themselves to these sorts of constraints.
If you keep all calculations server side, in a trusted computing environment, you do not have this concern.
Increasing data API expressiveness introduces new security concerns
As I discuss in the API Churn/Security Trade-off post, there are security concerns that become more and more elaborate as you increase the expressiveness of your data API. Again, the problem is that the client is an untrusted computing environment and, therefore, any tools you give to your front-end developers you are also giving to potentially hostile users.
This is not a concern on the server side, where the typical situation is a completely open and expressive data API (e.g. SQL or a data store’s native client.) Giving a tool to your server-side developers does not have the same security ramifications that giving it to your client-side developers does.
#4 - Decouple your UI and Data APIs
This will be controversial, but hear me out: I think it is better to separate your application UI from your data API because they have different target audiences.
To borrow a quote from the “API Churn” article above:
I don’t even argue anymore. Projects end up with a gazillion APIs tied to screens that change often, which, by “design” require changes in the API and before you know it, you end up with lots of APIs and for each API many form factors and platform variants.
What we see here is a data API engineer dealing with UI API needs. UIs are inherently fiddly and prone to churn. They often require specialized queries in order to make them perform well. This is in contrast with the mandate of most data (JSON) APIs, which need to be general data access tools, all things to all possible clients, within the security constraints mentioned above.
By decoupling your data (JSON) and application UI (HTML) APIs, you remove this mismatch in needs and can end up with cleaner implementations of both.
#5 - REST/HATEOAS Without Tears
One of the great technical tragedies of the last couple of decades has been the fall of REST due to its misapplication in data APIs and the concomitant obscurity that HATEOAS lingers in.
The technical community is picking up the pieces on the data side with newer technologies like GraphQL and I applaud that: REST was never going to be a great fit for data (JSON) APIs since it required a hypertext (e.g. HTML) for a lot of its power.
But let’s not throw the baby out with the bath water. Remember, REST was a description of the web architecture, not a prescriptive checklist to follow. All the old, clunky web applications that used reasonable URLs were already basically following that architecture. And that was a good thing! What was bad was the clunkiness of the applications, not the general network architecture which had, and still has, a bunch of benefits to it.
Fortunately there is a good, solid way to implement smooth, modern UIs that stays true to the original description of REST and, in fact, expands your ability to work with a lot of aspects of it (e.g. HTTP method support). By using the server side for your application logic and HTML for your UI API network transport, you can implement REST and HATEOAS without even really thinking about it, and enjoy all the benefits described in Roy Fielding’s dissertation.
Conclusion
So, there are five good reasons to consider a server-side architecture for your next web application. Your mileage may vary, of course: going server-side isn’t for every application. But I think it is a viable option for many, perhaps even most, web applications, and carries some nice benefits along with it.
Sure, it’s going against the grain these days. But what fun is going with the crowd anyway?
{kind=link}
Carson / @carson_gross